
Are you curious to learn how Amazon Web Services (AWS) Glue can help your organization increase efficiency and optimize data management? AWS Glue is a fully managed, serverless data integration service that helps businesses quickly and cost-effectively prepare and load their data for analytics and machine learning. This article covers the features and benefits of AWS Glue, and how to get started. With easy-to-use tools and a range of powerful features, AWS Glue can help your business scale up data management and data integration operations quickly, cost-effectively, and securely. Get ready to learn how AWS Glue can help you get the most out of your data!
Introduction to AWS Glue
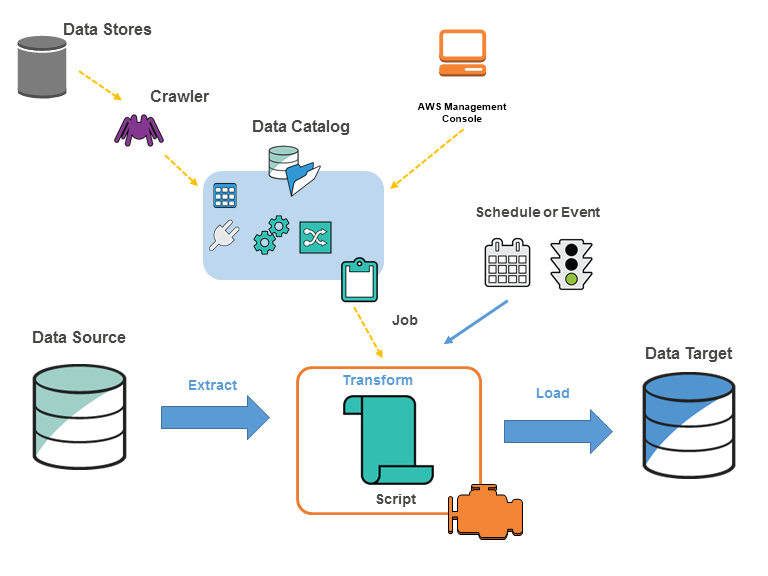
AWS Glue is an amazing cloud computing platform that helps to streamline the process of ETL (Extract, Transform, and Load) operations. It is the perfect solution for developers and data engineers who are looking for an automated and integrated way to access, transform and store their data in the cloud. AWS Glue is a fully managed and cost-efficient service that allows you to easily set up, manage and monitor ETL jobs. It comes with a wide range of features and capabilities, such as data integration, data transformation, data loading, data cataloging, and job scheduling. With AWS Glue, you can easily connect to multiple data sources, such as Amazon S3, Amazon RDS, and Amazon Redshift, and start building ETL pipelines quickly and efficiently. With its intuitive UI and rich feature set, you can quickly create custom ETL jobs that can be used to transform, clean and store your data in the most efficient way. AWS Glue is definitely the go-to tool for anyone looking to maximize their data processing and storage capabilities in the cloud.
Understanding AWS Glue’s Architecture
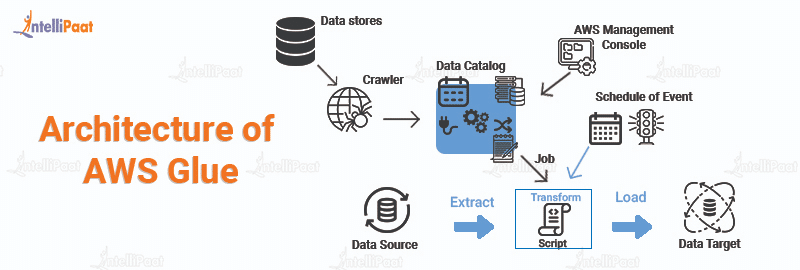
AWS Glue is an amazing cloud-based platform that makes it easy for developers to quickly create, deploy, and manage data pipelines. By leveraging the power of the cloud, AWS Glue helps developers quickly and easily create and maintain data pipelines that can handle large amounts of data processing tasks. The architecture of AWS Glue is designed to ensure that all data is processed in an efficient and secure manner. It is composed of two main components – the AWS Glue Data Catalog and the AWS Glue Execution Environment. The Data Catalog stores all the metadata related to the data sources and targets, while the Execution Environment is responsible for actually running the ETL jobs. The Execution Environment allows users to create custom transformations and jobs that can be used to move and transform data. With the help of AWS Glue, developers can quickly and easily create data pipelines that are able to handle large amounts of data processing tasks.
Benefits of Using AWS Glue
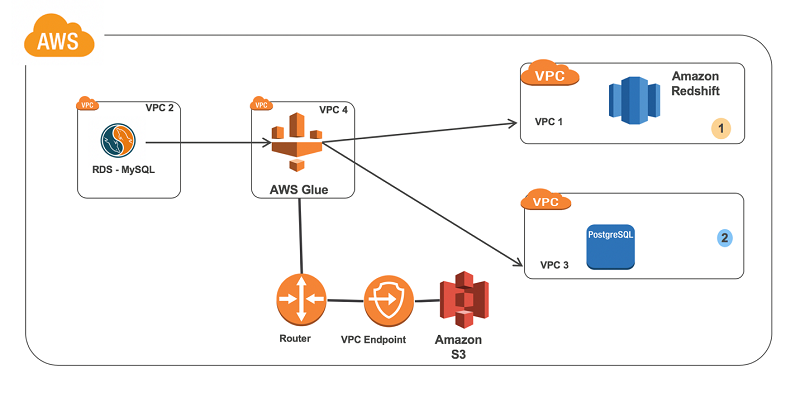
AWS Glue is an awesome tool for businesses of all sizes that are looking for a cost-effective and time-efficient way to manage their data. With AWS Glue, you can quickly and easily build, maintain, and scale data pipelines across multiple data sources. You can also automate data cataloging, data cleaning, and other data preparation tasks that would otherwise take up valuable time and resources. Plus, AWS Glue allows you to streamline your data integration process, reduce costs, and gain insights into new trends. There are even more benefits to using AWS Glue, such as the ability to save money on IT costs, create data lakes quickly and easily, and integrate with other Amazon Web Services (AWS) products. With all these advantages, AWS Glue is an essential tool for any business looking to streamline their data management process.
Automating Data Processing with AWS Glue
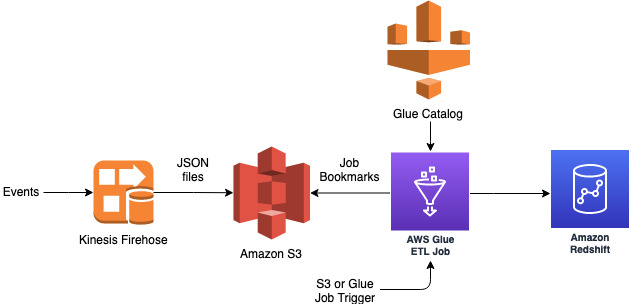
AWS Glue is a great tool for automating data processing and making it easier for data professionals to build and maintain data pipelines. With AWS Glue, you can quickly build and deploy data processing pipelines that are fully managed and optimized for performance. You can define workflows and schedule them to run at regular intervals, so that your data is always up to date. You can also define custom transformations and code your own custom logic to make sure your data is exactly how you want it. AWS Glue provides an easy-to-use interface that makes it simple to use and maintain. With AWS Glue, you can make sure your data is always fresh and accurate, so you can focus on creating more value for your business.
Best Practices for Using AWS Glue
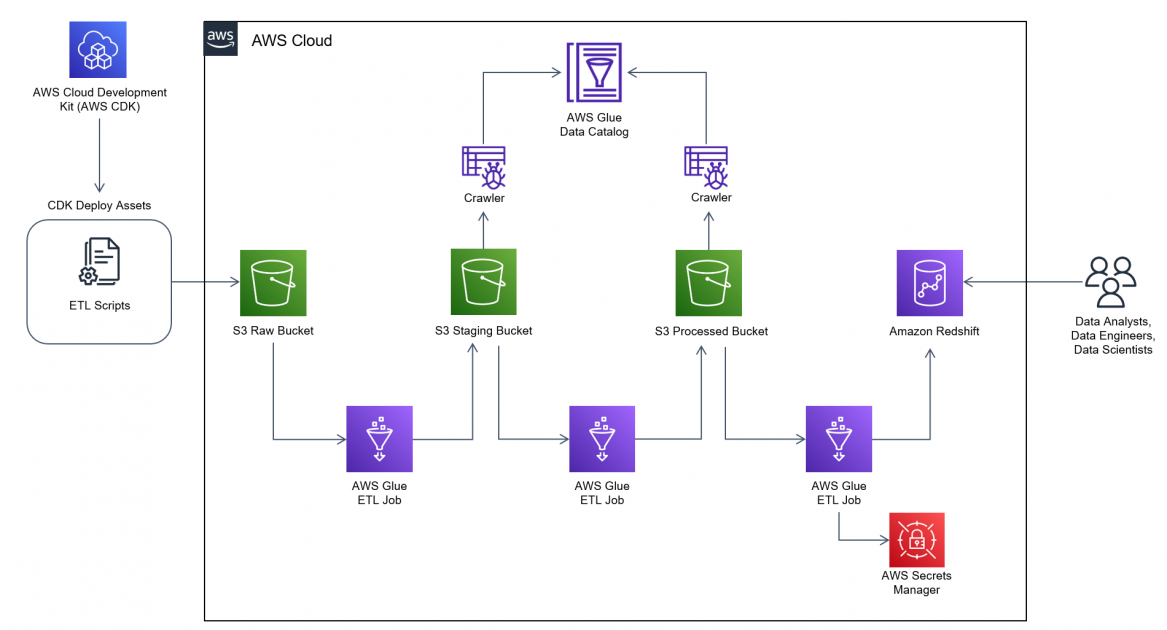
When it comes to using AWS Glue, there are some best practices that can help you get the most out of the technology. First off, it’s important to take advantage of the AWS Glue Data Catalog, which is a repository that stores various metadata information. This can help you organize and manage your data, making it easier to access and process. Additionally, you should use the AWS Glue Crawler to discover data and create tables in the Data Catalog. This will help you ensure that the Data Catalog is up to date and accurate. Finally, when running AWS Glue jobs, it’s important to use parameters to control the behavior of your job. This will make it easier to debug and troubleshoot any issues that you may encounter. By following these best practices, you can make sure that you are getting the most out of AWS Glue.

GIPHY App Key not set. Please check settings